The Observation Unit Set (OUS) used by ALMA serves multiple purposes:
- an organizational structure for separating multiple types of data which are generated from the high-level Science Goals defined in a proposal.
- a grouping mechanism for processing data, allowing for hierarchical data processing (calibrate data from 2 separate configurations, then combine them for a single image)
- a state-keeping mechanism for what has happened to each organizational level
For the time being, the EVLA mostly needs the latter two types of information (similar to Daniel's notion of the make-like workflow engine). SRDP will likely move us toward automatic decomposition of proposals into Scheduling Blocks (SBs), with the possibility for similar multiple-configuration proccessing. Fundamentally, consider an OUS-like structure to be a metadata analog to our filegroups: It links the 'prerequisites' for an archived product to the generating workflow and to the product itself:

The OUS is a recursive structure. Any given OUS contains a link to the product(s) it produced, and the starting point for that processing: One or more EBs, or other OUSs. Let's try and organize the VLASS single epoch processing in this structure:
Calibration: Calibration is performed on one or more EBs, and results in calibration tables which are archived. For a multiple EB calibration, the tables are not necessarily applicable to any individual EB. The calibration tables are linked to the OUS, providing the more appropriate relationship. Once the calibration tables are archived, the OUS is marked complete, indicating that the linked data can be restored. I this case, the OUS links directly to the EB(s) to be processed and the calibration tables.
Imaging: In order to perform imaging, you need a calibrated measurement set (which are not archived). The precursor for imaging, then would be one or more OUSs like that discussed above (which link the necessary pieces to create the calibrated measurement set). The resultant products here are the image set created.
Catalogs: From the images created above, we want to make a catalog to facilitate the creation of the coarse cubes. The precursor is then the structure created above, and we perform the (yet to be determined) processing upon those images which will create the catalog needed for the masking process in cube computation. It is unclear whether catalogs will be created in a 1:1 correspondence with images, or some other relationship. Because we can have as many 'child' OUSs for the precursor information as necessary, that doesn't need to be settled right away. Whatever is decided, these catalogs will be archived, and this OUS will be used as a prerequisite below.
Cubes: These require both a calibrated measurement set and a catalog in order to be created properly. Each cube would require both the catalog and the calibrated measurement set in order to perform the reduction. As I understand it, a cube itself is going to be an organizational structure (another grouping of images beyond the image set), but that is still under discussion.
In order for this to work, we will need to define metadata structures for the products we will ingest. We already have this for images, but we need to create corresponding structures for calibration tables, catalogs, and cubes.
Questions of Functionality:
What types of these OUSs are we going to need, and how can we keep the system extensible as the needs of the users expand?
We may need to handle some sort of 'incremental update' functionality as well. For SRDP, they may want some reactive capability: Consider a monitoring project. Overall, there will be 50 observations, evenly spaced, of a particular target. Those observations are all generated from the same SB, but we don't know what the EB's name will be beforehand. The monitoring project OUS might pre-create a child OUS which is looking for the next EB from this SB. Once an EB is created it is placed into the child OUS, and a new child is created, until we have all 50. At that point the parent OUS might have processing to do (make a time-lapse movie, for instance). How do we handle that type of functionality?
Caveat: Each Alma Science Goal is restricted to a single receiver (or is it a single total IFLO setup?). Any attempt to restructure EVLA data will likely need to take account of factors other than just configuration.
Backward Compatability:
ALMA creates a 3-layer structure of OUSs by default, but only uses the lowest level (also called a Member OUS or MOUS) for any automated processing. The upper layers were envisioned to be used in more complicated imaging or analysis tasks, but those are neither in use, nor likely to be used in the near future (~10 years). For the time being, all ALMA data is managed within a single OUS, which is operated upon multiple times (as of October 2017), first of all to calibrate and ingest the calibration tables, and secondly to perform imaging on that same group of data. Both sets of products are tied to the MOUS level of the structure. As we create a similar structure, we should be careful to acknowledge where our similarities with the ALMA structure are, so we can display that as relevant (both for the comfort of ALMA users, and as an SRDP requirement).
Multiple-products:
We already make available mulitple calibration tar files when they exist, but there is no information determining how they differ, or why a user might prefer one over the other. That type of information should be part of the metadata we provide (either within the individual product tables, or via connections to the creating workflow). The recalibration would constitute another OUS, and should specify how it differs from the standard process (additional flagging, parameter changes to tasks, etc).
What's in a name?
The name 'Observation Unit Set' is not a particularly informative name. There is also quite a bit of resistance to importing ALMA concepts into EVLA processes. Both can be remedied with another name for the concept. What's a better name for this structure? If we want one, we need to be quick. The next-gen PST requirements committee seems to be leaning toward the name 'Program'. Any other ideas? Pipeline Processing Unit? Data Analysis Group? Set For Reduction?
For the time being, we will keep with the ALMA type names (MOUS, etc), until there is sufficient objection.
Looks like we're going for Pipeline Processing Group (sans objections).
Product Intent Group! We've got recursive PIGs.
We're going for the simpler answer: an alma_ous table which tracks basic information, and only for ALMA data.
Implementation: (See: SSA-5123 - Getting issue details... STATUS )
We'll add a filegroups-like table which tracks basic information about the OUSes.
- alma_ous
- metadata:
- name – uid
- type – MOUS, GOUS, SOUS
- project_code (nullable, if we have a parent_ous_id)
- NOTE: calibration status handled by non-null link below:
- structure:
- alma_ous_id (Primary Key, sequence generated)
- parent_ous_id (nullable, if we have a project code)
- calibration_id (nullable, foreign key link to calibration table entry, if it's been released)
- metadata:
(Move this to a new page) Product Structure Generalization:
A further potential database refactor (part of this change, or later?) which has been proposed is to unify the filegroup structure for archive products, following the pattern we've set for image_sets:
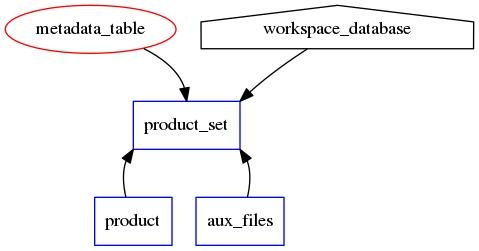
We don't current have auxiliary files for anything other than images. However, using this it would be readily possible to separate the weblog & PPR from the calibration tables (for instance), to provide easier access for the weblog review capability which has been requested. Another use case which comes to mind are correlator logs, which are currently not ingested for any of our arrays.
Software Implications:
These are far, far harder to solidify until some of the above is solidified. Certainly there are implications for:
- ingestion
- Solr
- archiveIface
However, the details will wait for a more solidified design.