Theory:
The Observation Unit Set (OUS) used by ALMA serves multiple purposes:
- an organizational structure for separating multiple types of data which are generated from the high-level Science Goals defined in a proposal.
- a grouping mechanism for processing data, allowing for hierarchical data processing (calibrate data from 2 separate configurations, then combine them for a single image)
- a state-keeping mechanism for what has happened to each organizational level
The OUS was initially envisioned as a recursive structure, laid out at proposal time in order to create a science product meeting particular scientific criteria. The structure would account for both the observational and processing needs for the result. Intermediate products are tied to the organizational level at which they were generated.

Practice:
Operationally, ALMA restricts itself to 3 OUS levels, rather than the full recursive functionality. ALMA proposals are organized as a set of Science Goals which specify high level requirements (receiver band, sensitivity, resolution, and largest angular scale). Those requirements are then used to determine which subsystems and array configurations are required to obtain the necessary data. After relevant groupings of data are collected, data reduction can begin.
Each Science Goal is assigned a SOUS (Science Goal Observation Unit Set, sometimes called an SGOUS). Within the SOUS lies a single GOUS (Group Observation Unit Set) which organizes the different observations. In theory, there could be multiple GOUSes within a SOUS, but ALMA does not currently support that use case. Within a GOUS are multiple MOUSes (Member Observation Unit Sets), with each MOUS corresponding to data taken with a particular ALMA sub-instrument in a particular configuration. This way, all data taken in the main array's 43-5 configuration are grouped together for processing, but kept separate from the same Science Goal's observations with the Alma Compact Array.
All official data processing for ALMA (at the Alma Regional Centers, such as in Charlottesville) occurs at the MOUS level. Once the expected number of observations are accumulated, the calibration & imaging pipelines are run. The results of those pipelines are then archived tied to the MOUS's identifier. Sometime later, ALMA may expand to creating multi-configuration images at the GOUS level, but that is not envisioned for the near future.
The AAT/PPI is currently tracking all 3 OUS levels in our metadata for reference. As of version 3.6, it also provides the ability to restore calibrated measurement sets for an MOUS, provided that the data was calibrated entirely by the CASA pipeline.
Representation in the AAT/PPI:
Due to both ALMA and the EVLA using the Science Data Model format, it was relatively easy to incorporate ALMA execution blocks into the AAT/PPI system. In order to handle the OUS information, however, new table was added:
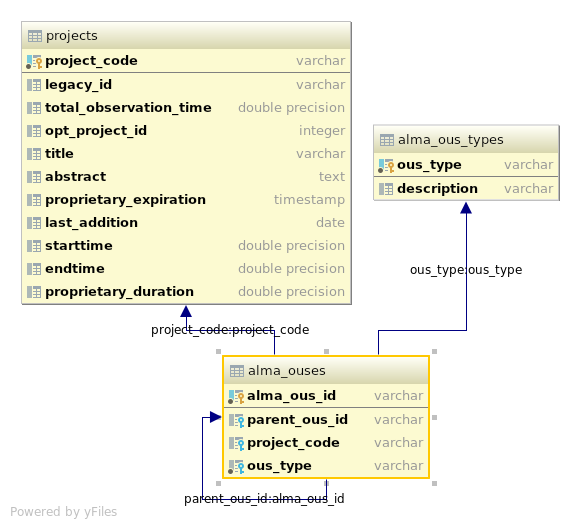
In the alma_ouses table, the SOUS/GOUS/MOUS (with those being the types defined in alma_ous_types) structure is recorded, with the SOUS maintaining a connection to the project, and the sub-OUSes linking to their parent. In addition, the alma_ous_id column was added to the execution_blocks table, providing a link from that level to the larger structure.
3 Comments
Stephan Witz
I had some time to think about this all while I was on the road, this is what I came up with, hopefully it is simpler.
I posit the PPG represents only three things: the purpose (calibration, imaging, or calibration + imaging), the dependencies needed to make it happen, and whether or not the dependencies are met. "I intend for these three executions to be calibrated together into a group, I intend for these two calibration groups to be imaged together". The PPG doesn't hold the specifics of the products associated with the PPG.
Using that definition I'll try to answer the two nasty questions that came up during the talks.
Some additional points:
I've asked Jeff for some clarifications that should tell me if I'm going in the right direction.
Does this make sense?
James Sheckard
This conceptual/actual split makes sense. Especially with what Jen has in place already (you can get the workflow details joining via the product filegroup).
If the PPGs are meant to be generic (i.e. all calibrations bundled in one PPG, all images from those calibrations bundled), we'll loose any easy access to provenance. That's ok, but something to note.
Under this scenario I can still see PPGs being used more than once (i.e. having multiple parents): VLASS cumulative imaging, multi-configuration (both ALMA and EVLA) imaging, multi-band imaging (or is that not a thing?). So this might simplify the PPG→EB many-to-many, I think PPGs still need the additional flexibility of the many-to-many relation between them.
Stephan Witz
I spoke with Jeff, the basic ideas in my comment above are true. I do think 'pipeline processing group' as a name misses the mark a bit and implies things about what the structure will structure will store that aren't true, a better name might be 'processing intention group'.